import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from itertools import combinations
if __name__ == "__main__":
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
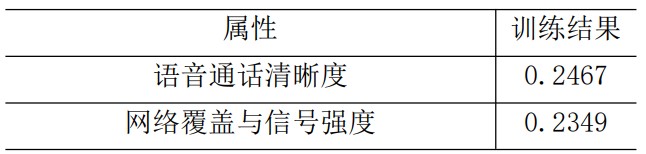
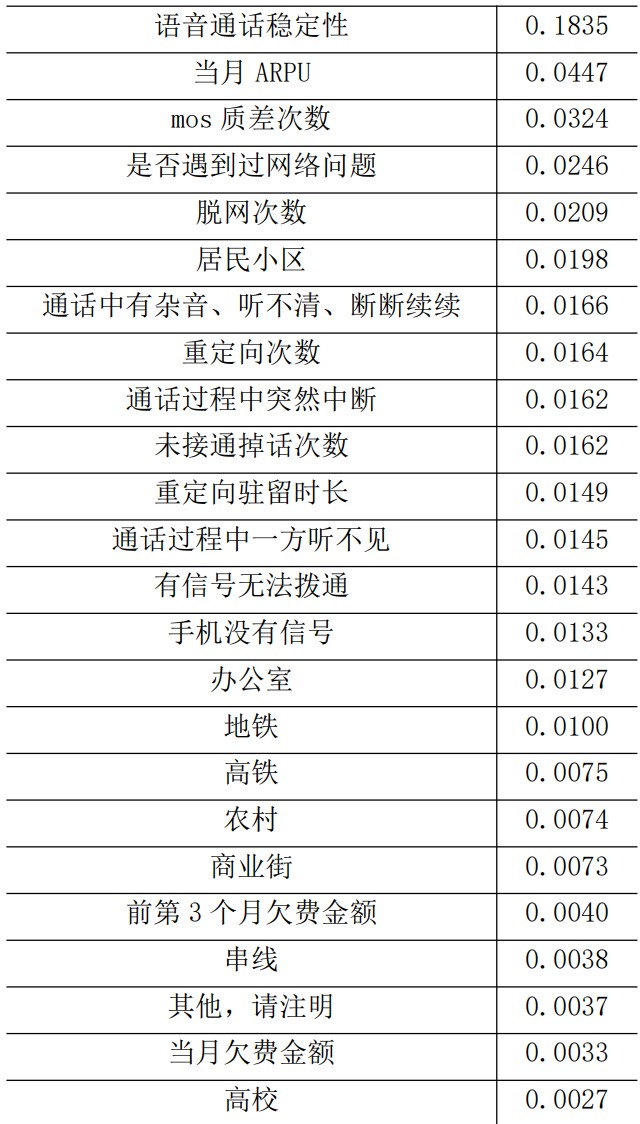
feature = '网络覆盖与信号强度','语音通话清晰度','语音通话稳定性','是否遇到过网络问题','居民小区','办公室','高校','商业街','地铁','农村','高铁','其他,请注明','手机没有信号','有信号无法拨通','通话过程中突然中断','通话中有杂音、听不清、断断续续','串线','通话过程中一方听不见','其他,请注明.1','脱网次数','mos质差次数','未接通掉话次数','重定向次数','重定向驻留时长','ARPU(家庭宽带)','是否4G网络客户(本地剔除物联网)','当月ARPU','前3月ARPU','当月欠费金额','前第3个月欠费金额'
path = 'f1_.csv'
data = pd.read_csv(path, header=None)
x_prime = data[list(range(1,31))]
y = pd.Categorical(data[0]).codes
x_prime_train, x_prime_test, y_train, y_test = train_test_split(x_prime, y, test_size=0.3, random_state=0)
pairs = [c for c in combinations(range(1,31), 30)]
feature_pairs = []
num = len(pairs)
for i in range(num):
feature_pairs.append(list(pairs[i]))
for i, pair in enumerate(feature_pairs):
x_train = x_prime_train[pair]
x_test = x_prime_test[pair]
model = RandomForestClassifier(n_estimators=100, criterion='entropy', max_depth=10, oob_score=True)
model.fit(x_train, y_train)
importance = model.feature_importances_
for j in range(0,30,3):
print(feature[j], ':', importance[j], feature[j+1], ':', importance[j+1]
, feature[j+2], ':', importance[j+2])
y_train_pred = model.predict(x_train)
acc_train = accuracy_score(y_train, y_train_pred)
y_test_pred = model.predict(x_test)
acc_test = accuracy_score(y_test, y_test_pred)
print('OOB Score:', model.oob_score_)
print('\t训练集准确率: %.4f%%' % (100*acc_train))
print('\t测试集准确率: %.4f%%\n' % (100*acc_test))
|